Hadoop
Hadoop is a Java-based open source platform for storing and analyzing large amounts of data. The data is stored on low-cost commodity servers that are clustered together.
Hadoop is a Java-based open source platform for storing and analyzing large amounts of data. The data is stored on low-cost commodity servers that are clustered together. Concurrent processing and fault tolerance are enabled via the distributed file system. Hadoop, which was created by Doug Cutting and Michael J, uses the Map Reduce programming architecture to store and retrieve data from its nodes more quickly. The Apache Software Foundation manages the framework, which is released under the Apache License 2.0. While application servers' processing power has increased dramatically in recent years, databases have lagged behind due to their limited capacity and speed. Had loop, created by Doug Cutting and Michael J, employs the Map Reduce programming model to store and retrieve data from its nodes more quickly.

There are direct and indirect benefits from a business standpoint as well. Organizations save money by deploying open-source technologies on low-cost servers, which are primarily in the cloud (though occasionally on-premises).
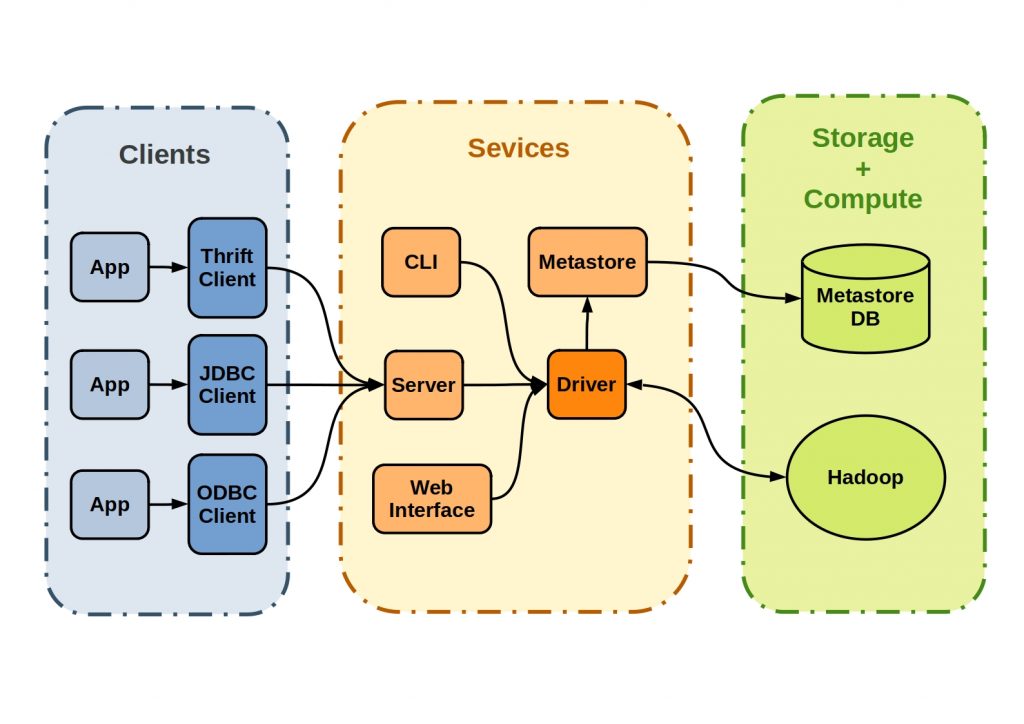
Furthermore, the ability to collect large amounts of data and the insights gained from crunching that data leads to better real-world business decisions, such as the ability to focus on the right customer segment, weed out or fix inefficient processes, optimize floor operations, provide relevant search results, perform predictive analytics, and so on. Hadoop is more than a single application; it's a platform with a number of interconnected components that allow for distributed data storage and processing. The hadoop ecosystem is made up of these components. Some of these are key components that form the framework's base, while others are supplemental components that add to Hadoop's functionality. There are direct and indirect benefits from a business standpoint as well. Organizations save money by employing open-source technologies on low-cost servers, which are usually in the cloud (though occasionally on-premises).
Regardless of whether you're looking to utilise AWS for development, preparedness, cost investment money, operational competence, or all of the above, you've come to the right place.
They require support in overcoming the challenges of migrating to and employing cloud-based foundations, managing current IT resources, developing their micro services models, enhancing their dexterity, and modifying APIs – all while lowering IT costs. will work with you to solve your most complex and unique cloud problems with AWS, supporting you in generating new revenue streams, increasing efficiency, and delivering incredible experiences. Whether you want to use AWS for advancement, nimbleness, cost savings, operational productivity, or all of the above, you've come to the right place. Rackspace Technology, in collaboration with professionals from the recently acquired Inteca, brings the most cutting edge AWS capabilities to work for your benefit, with over 2700+ AWS accreditations and 14 center abilities.